In general these include the following. If the performance of the model on the training dataset is significantly better than the performance on the test dataset then the model may have overfit the training dataset.

Ways To Evaluate Machine Learning Model Performance Machine Learning Models Machine Learning How To Memorize Things
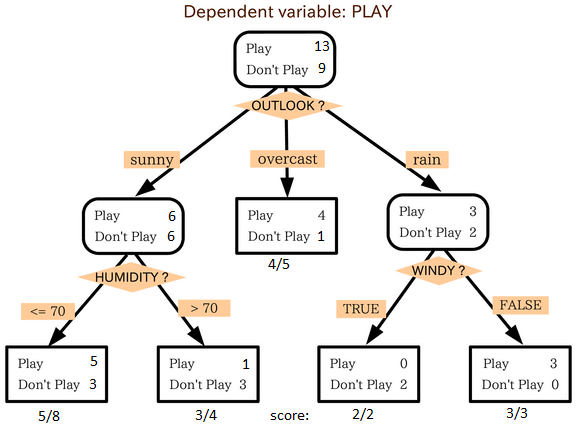
Figure 1 illustrates the point.

. Low variance in model performance means that model predictions are more reliable and lower risk. Therefore Hyperparameter optimization is considered the trickiest part of building machine learning models. Set up a machine learning pipeline that compares the performance of each algorithm on the dataset using a set of carefully selected evaluation criteria.
We can identify if a machine learning model has overfit by first evaluating the model on the training dataset and then evaluating the same model on a holdout test dataset. While defining the architecture of a machine learning model it is usually not obvious to come across an optimal one. This is why you need to optimize them in order to get the.
Compare scores for two different but related models using the same set of data. Most of these machine learning algorithms come with the default values of their hyperparameters. And the parameters which are used to define this architecture are referred to as hyperparameters and the process of searching the right architecture for the.
Evaluate the model on your problem and use the result as an approximate top-end benchmark then find the simplest model that achieves similar performance. Machine Learning with h2oautoml from the h2o package. Turns out the best model is the AdaBoostClassifier.
The problem with this approach is it could take a VERY long time. Yet depending on the choices of weights of recall and precision in the calculation we can generalize the F1 measure to other F scores based on different business needs. Models can have many hyperparameters and finding the best combination of parameters can be treated as a search problem.
Cross-validation allows us to see how performance varies across multiple tests. Two simple strategies to optimizetune the hyperparameters. For a complete list of metrics and approaches you can use to evaluate the accuracy of machine learning models see Evaluate Model component.
The data feed into this that helps the model to learn from and predict with accurate results. Automating choice of learning rate. Choosing the Right Algorithms.
But the default values do not always perform well on different types of Machine Learning projects. I would normally pick the best baseline model and perform a GridSearchCV on it to further improve its baseline performance. For any given data set we want to develop a model that is able to predict with the highest degree of accuracy possible.
If you want your model to be smart then your model has to predict correctly. For that large errors receive higher punishment. One approach is to try every possible machine learning model and then to examine which model yields the best results.
The parameters used in the algorithm. How to Determine What Machine Learning Model to Use. This function takes automated machine learning to the next level by testing a number of advanced algorithms such as random forests ensemble methods and deep learning along with more traditional algorithms such as logistic regression.
The best one is automatically selected. The main takeaway is that we can now easily achieve predictive. Generate scores on the model but compare those scores to scores on a reserved testing set.
There are more than 100 statistical tests available and it is a. Hence choosing the right algorithm is important to ensure the performance of. But RMSE is highly sensitive.
24 of the applicants in Segment 1 or 2400 2410000. In summary the best performing learning rate for size 1x was also the best learning rate for size 10x. Time to train can roughly be modeled as c kn for a model with n weights fixed cost c and learning constant kflearning rate.
The trick here is to use cross-validation to determine which model will perform best on the data. In machine learning there are many levers that impact the performance of the model. Machine learning is closely related to computational statistics.
When you have more samples then reconstructing the error distribution using RMSE is more reliable. In other words when the model predicted a positive class it was correct 75 or the time. However what if hypothetically speaking the model that performed best as a baseline model in this case AdaBoost only improves 1 through hyperparameter tuning.
This means your True Positives and True Negatives should be as high as possible and at the same time you need to minimize your mistakes for which your False Positives and False Negatives should be as low as possible. RMSE is a better performance metric as it squares the errors before taking the averages. The highest F1 score of 1 gives the best model.
Similarly to determine the accuracy of a machine learning model suppose I have 100 points in the test dataset and out of which 60 points belong to the positive class and 40 belong to the negative. What works well for one problem may not work well for another. There are dozens of machine learning algorithms and each one has different run times.
In our example precision is 075 450600. Grid search and 2. We are putting equal importance on the precision and recall for the F1 score.
Although there are many hyperparameter optimizationtuning algorithms now this post discusses two simple strategies. It is calculated by dividing the number of true positives in the matrix by the total number of predicted positives. Machine learning algorithms heavily rely on statistical tests for execution.
The quantity and quality of the data set. To do this the machine is tasked with selecting the optimal model architecture. A machine learning model will rank loan applicants into high-default-risk segments to low risk segments.
It performs particularly well when large errors are undesirable for your models performance. Algorithms are the key factor used to train the ML models. Ideally wed like to select the features and model parameters that give the best performance with the lowest variance in model performance.
Select a machine learning method that is sophisticated and known to perform well on a range of predictive model problems such as random forest or gradient boosting.
Commonly Used Machine Learning Algorithms Data Science
Supervised And Unsupervised Machine Learning Algorithms

Machine Learning Algorithms Their Use Cases In 2021 Machine Learning Algorithm Use Case


0 Comments